2024-07-3119:33 Status:NESPseudoCS50
Efficiency can be determined by a program’s overall time taken to execute, storage take, any redundancy etc. its efficiency can be denoted by ‘O’ (bid O notation). Algorithms are essentially a set of recursive instructions: Where recursion is using the same function within itself to reduce redundancy of code often denoted by (n!) = fact(n) (as ! is used to express an inversion). You need to implement a base case to break the loop of recursion, otherwise it will repeat forever. It will call itself in a slightly altered way. e.g. n==1 (fact(1) =1)
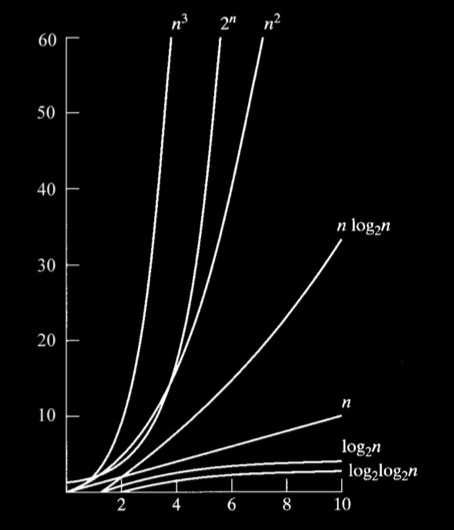
As n functions infinitely increase they are all denoted by n regardless of their rate (O), whereas log n functions are much more efficient and can be denoted by log (O) etc.
For optimal efficiency, n is as low as possible, when n is equal a constant, it has been optimized
Order of efficiency from worst (n = high) to least (n is low)
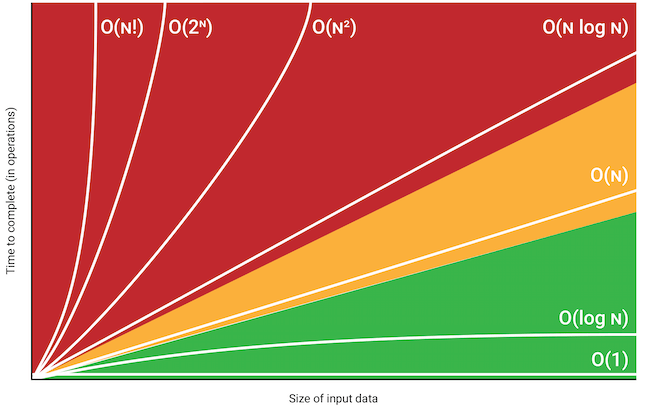
Generally, it is ideal for constant time complexity, and detrimental for anything above O(n).
The difference between Big O notation and Big Ω notation is that Big O is used to describe the worst case running time for an algorithm. But, Big Ω notation, on the other hand, is used to describe the best case running time for a given algorithm.
If the efficiency between Ω and O are the same it is denoted by theta
Linear search searching from top to bottom for a specific value
O = n in that it takes n amount of times to find the desire value
Ω = 1 because the minimum amount of searches that can be taken = 1 (if the desired value happens to be the first one listed)
Algorithms are often performed on specific Data structures and apply/work better if the data set is organized in a specific way. To create an encapsulation of data in C:
typedef struct
{
string name;
string phone number;
}
person;
int main(void)
{
person people[n];
people[0].name = “Carter”;
people[0].number = “4126736272”;